- Published on
ShuffleNet V2 - FLOPs can lie
- Authors

- Name
- Rand Xie
- @Randxie29
Recently, I am reseaching on how to improve model inference speed on edge device (specifically Jetson Nano). The target is to minimize latency under limited computation power. Here's the spec for Jetson Nano, where the peak performance is 472 GFLOPs.
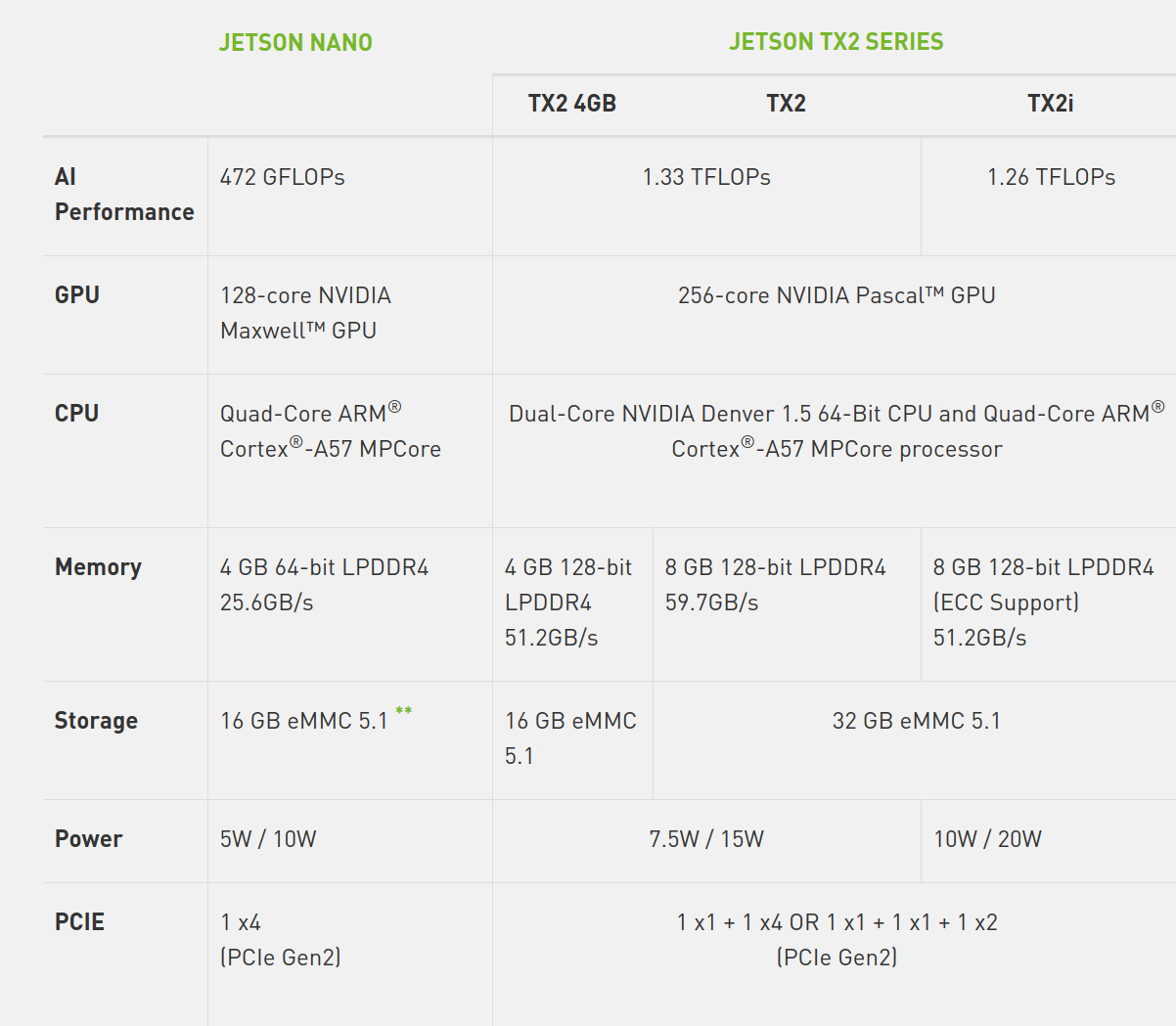
As I continue to optimize the inference speed, I realize that FLOPs is not the only factor affecting the latency and this assumption is confirmed by the paper ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design. In this post, I will outline a few learning from this paper.
FLOPs is an indirect metric, there's more to consider
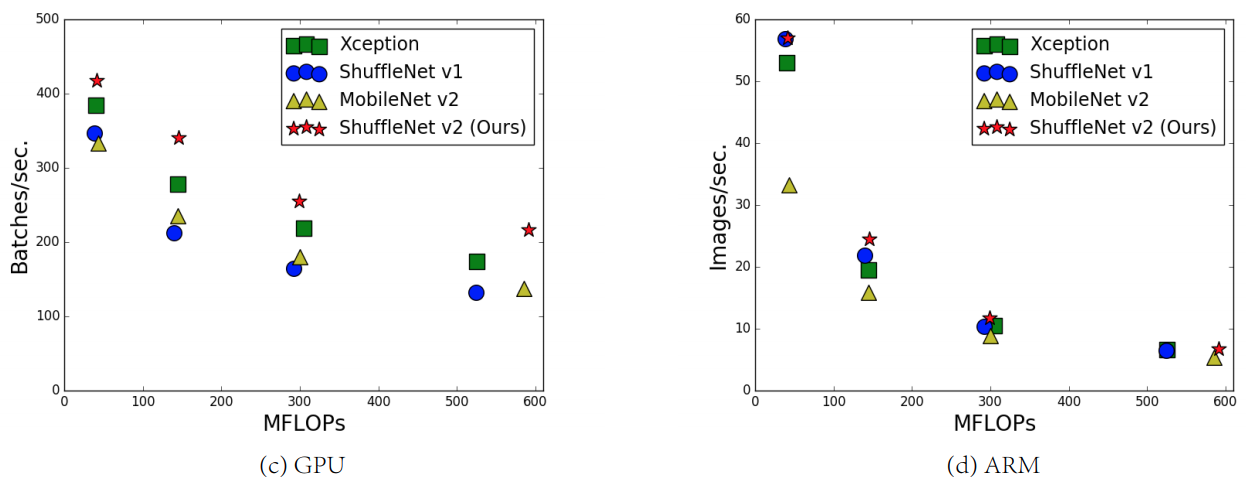
The paper evaluates batches/sec for different network under different FLOPs. Here's what I read from the comparison:
- Networks with similar FLOPs can have quite different speeds. Therefore, it's not sufficient to evaluate computational complexity only based on FLOPs.
- FLOPs is positively correlated to the speed. For the same network, an increase in FLOPs will decrease batches per second.
- The performance characteristics can vary a lot between GPU and CPU. Therefore, the deployed hardware plays an important role.
Other important factors include:
- Memory access cost (MAC): this can be bottleneck on device with strong computing power like GPU. This's the reason why EfficientNet is not necessarily faster even though the FLOPs are greatly reduced.
- Degree of paralellism: for the same FLOPs, if the critical path is sequential, the performance can still be bad. A typical example is RNN.
Guide for efficient network design
- Equal channel width minimizes MAC
- Exccessive group convolution increases MAC
- Network framentation reduces degress of parallelism
- Element-wse operaions are non-negligible
These guidelines aligns with the section "FLOPs is an indirect metric", as they take MAC and parallelism into account.