- Published on
Embedding based retrieval
- Authors

- Name
- Rand Xie
- @Randxie29
Facebook recently published a paper embedding based retrieval in Facebook search to discuss how they use embeddings in FB's search system. In this post, I will go into the details and outline my major findings.
Overview
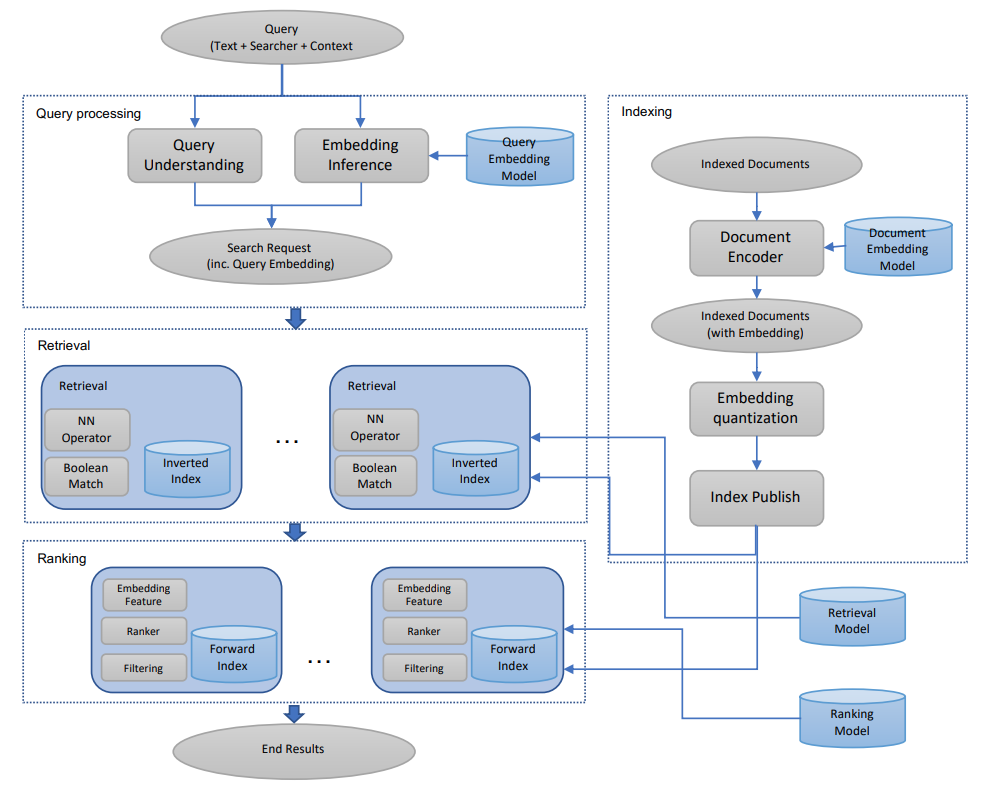
Search engine has a lot of similarities with a recommendation engine. In particular, both of them have a recall layer (retrieval) that retrieves a set of relevant documents, and a precision layer (ranking) that ranks the returned documents. Usually, the recall layer is the bottleneck to the downstream tasks, as the retrieval quality determines the final results. The precision layer uses a more complicated model to order the result from the recall layer.
The paper can be roughly splitted into 4 parts: modeling, feature engineering, serving and further optimization.
Modeling
Optimize recall
The search retrieval is formulated as recall optmization problem that optimizes top K recall:
, where represents the top K retrived documents.
As the metric can not be optimized directly, triplet loss is used to maximize the margin between positive pair and negative pair, where triplet loss is defined as
.
One thing that's mentioned is that the choice of margin can lead to 5 to 10 recall variance.
Define labels
Defining positive and negative labels is not trieval. In this paper, click is used as the positive signal while random samples from document pool are used as negatives. It's also mentioned that using non-click impressions can lead to much worse performance.
Feature engineering
In FB, the features can be in different form, e.g. text, locations, social graph embedding. For text features, character n-gram embedding with hashed word n-gram embedding (hashing to reduce vocabulary) are used together as a joined embedding. It's found that such embedding can help with fuzzy text match and optioinalization.
Serving
The serving pipeline uses FAISS to quantize the vectors, which is used to generate the inverted index. An offline pipeline is used to tune key parameters such as number of clusters, number of bytes for product quantization and number of clusters assigned to query embeddings.
Further optimization
This paper mentioned two direcitons to further optimize the system:
- Online hard negative mining: within a batch, using other positive documents that receive highest similarity score as hard negative samples.
- Embedding ensemble: combined models trained with different level of hardness.
Summary
This is a very practical paper with experience learnt from building a scalable embedding based search engine. The tricks mentioned in the paper are worth trying.