- Published on
Lessons Learned from Building a Text2SQL Product
- Authors

- Name
- Rand Xie
- @Randxie29
The launch of GPT-4 has inspired developers to create AI-native tools, with text-to-SQL conversion being a popular idea for several reasons:
- SQL is widely used by enterprises to manage tabular data.
- It offers a quick and direct business impact.
- Non-analyst roles can access and retrieve data without relying on data analysts.
My friend and I saw this opportunity as well, so we dedicated some time to developing a Text2SQL product. While we have successfully built the Minimum Viable Product (MVP), we ultimately made the decision not to launch it. Nevertheless, we believe that the lessons we learned throughout this journey are valuable and worth sharing.
In this blog post, I will delve into the details of our experience in creating a Text2SQL product, which we named "QueryCollab". I will discuss various aspects, such as how we assessed the tool's value, the key technical choices we made, and the UI decisions we implemented.
Assess the tool's dollar value
The dollar value of a tool per month can be estimated using the following formula: Dollar Value = Number of Users * Usage * Cost Saving per Usage
To provide a concrete example, let's say we are targeting a company with 500 employees, and the data analysts (those who use SQL to query data daily) make up 1% of the workforce. We assume that each data analyst writes 5 queries per day. If the Text2SQL product can help each data analyst save 10 minutes per query, it would save a total of 250 minutes per day.
In the United States, the national average salary for entry-level data analysts is $33 per hour (source: ZipRecruiter). Therefore, the tool would result in a saving of $4125 per month. Not bad, right?
This estimation is quite conservative because it doesn't take into account the potential communication cost between other roles who need the data and the data analysts themselves. Other roles, such as product managers or finance teams, may require data for their decision-making or financial analysis. The tool enables them to work more efficiently by allowing them to express their requirements in natural language and translate them into SQL.
Main Components
I hope that I have successfully conveyed the value of building a Text2SQL tool. At least, we have been convinced of its merits. Now, let's move on to determining the scope of what needs to be built.
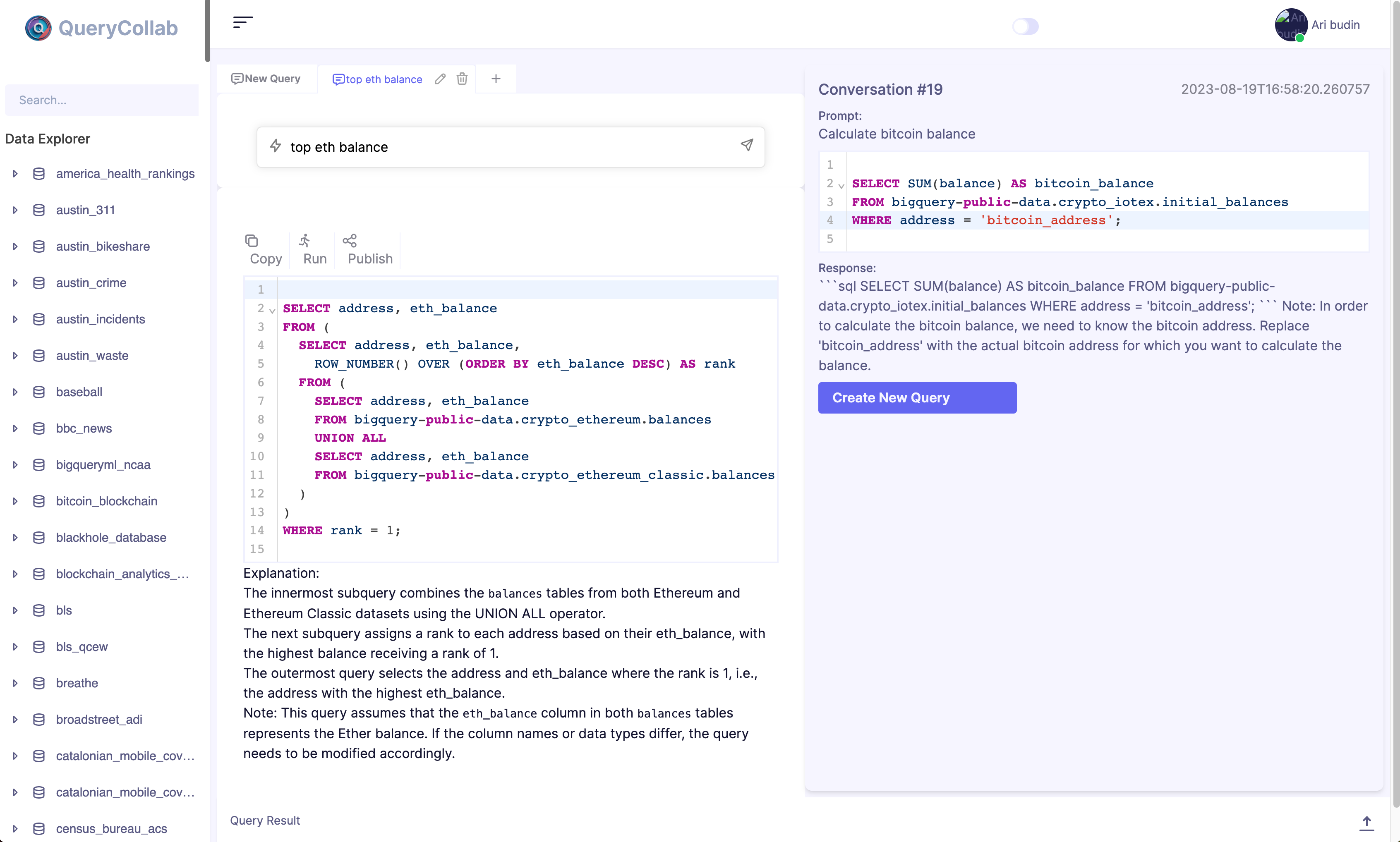
Earlier in this blog post, I provided a figure of what the product looks like. It consists of several core components:
- Crawler
- An input box that enables users to input their product questions
- A SQL editor resembling what you would find in platforms like Looker or BigQuery
Crawler
The Crawler is a vital component that supports the UI in the background. It performs the following tasks:
- Data Exploration: The Crawler continuously crawls the data lake to obtain up-to-date information. It identifies new tables and columns added to the data lake, ensuring that the data explorer remains updated.
- Column Description Generation: To facilitate data understanding, the Crawler retrieves sample data from various tables. By leveraging this sample data, it automatically generates or updates column descriptions.
During the product development, we continuously crawl the public datasets stored in BigQuery. In addition, we extend our crawler to crawl example queries in each BigQuery dataset. These example queries can be used as few shot examples for SQL generation.
Input Box that only supports single-turn conversations
In one of my previous blogs, I discuss why multi-turn conversation may not be the ideal solution for LLM based development tools. This insight was gained from our experience building the Text2SQL product.
During the development of Text2SQL, we realized that ChatGPT must support multi-turn conversations because it does not allow users to edit previous interactions. When additional context is needed to guide the LLM, the only available option is to utilize multi-turn conversations. However, for Text2SQL, users can simply go back to the input box and modify the question, thereby providing the necessary context. Using multi-turn conversations is not necessary in this case.
Furthermore, if users only require small corrections to the generated SQL, it is more efficient to edit the text directly rather than involving the LLM to make those modifications. As a result, we provided an SQL editor for users to manually modify the query.
SQL Editor
There's nothing fancy about this part. We used react-codemirror to build the SQL editor.
Lessons Learned
Now that we have discussed the various components of the product, let's summarize the main lessons learned. One pivotal question remains: is GPT-4 adequate for SQL generation, or is it necessary to fine-tune the model?
Unlike many Text2SQL startups, our perspective is that GPT-4 is indeed sufficient for SQL generation, as long as retrieval-augmented generation (RAG) is done correctly. It also means you should spend more time on RAG instead of fine-tuning. Allow me to explain the rationales behind this belief:
The primary challenge lies in generating "correct" SQL. This is because human language tends to be ambiguous, and there is a translation cost involved. To ensure accurate translation from human language to SQL, it is crucial to provide additional context within the prompt, rather than focusing solely on improving the SQL generation part.
Language models do not provide any guarantees in terms of semantic correctness, and they are unlikely to do so in the near future. Semantic correctness refers to the accuracy of the meaning conveyed, beyond just syntax correctness, which is relatively easier to verify. For instance, if a product manager asks for the calculation of each state's population in the United States, the states stored in your table could be represented as "CA," "California," "california," or "CALIFORNIA." Even if potential state values are passed as input, it cannot be ensured that the where clause is utilizing the correct value. As a result, Text2SQL tools will continue to serve as a Co-Pilot, assisting users in the process. An effective Text2SQL product should prioritize streamlining the verification process, rather than solely pursuing first-shot code generation correctness.
In addition, I want to emphasize that a few Text2SQL products claim better performance than GPT-4 based on the Spider dataset. However, it is important to exercise caution. Firstly, the queries found in the Spider dataset are considerably different from what are typically encountered in day-to-day work scenarios. Secondly, these products may intentionally or unintentionally manipulate the benchmark. Lastly, the most significant challenge in constructing a Text2SQL product lies in comprehending the user's intent, which necessitates reasoning capabilities on par with GPT-4.
Based on our internal testing, GPT-4 proves highly usable when provided with sufficient context. Consequently, the crux of building a Text2SQL product is essentially constructing a search engine on the data lake. It is essential to ensure that all pertinent business contexts are incorporated into the prompt for SQL generation.
Final Thoughts
In the end, I want to make some predictions to the Text2SQL product field. It is crucial for a Text2SQL product to have a strong integration with the data lake and leverage tools that provide relevant business context, such as Slack and Google Docs. Various BI tools, including Looker, Bigquery, Snowflake, and Databricks, offer specific advantages in terms of data lake integration. On the other hand, when it comes to the business context component, an enterprise search engine like Glean provides distinct benefits. In fact, an enterprise search engine is positioned favorably to address the challenges of the Text2SQL product field, as accessing a data lake is relatively straightforward compared to aggregating information from multiple sources.
Solving the Text2SQL problem end-to-end can be quite challenging for small startups. As a better strategy, these startups may consider building on top of BI tools and enterprise search tools. Another alternative is to focus on developing query languages in specific industries, such as the healthcare sector. By adopting these approaches, small Text2SQL startups can leverage existing infrastructure and domain-specific requirements to facilitate their development and provide value to their target audience.