- Published on
Use Einstein Notation to derive Backpropagation
- Authors

- Name
- Rand Xie
- @Randxie29
Recently, I hit into a great book published Huggingface that talked about scaling LLM. One of the figures triggered my thinking - how to derive the gradient flowing back in the compute graph.
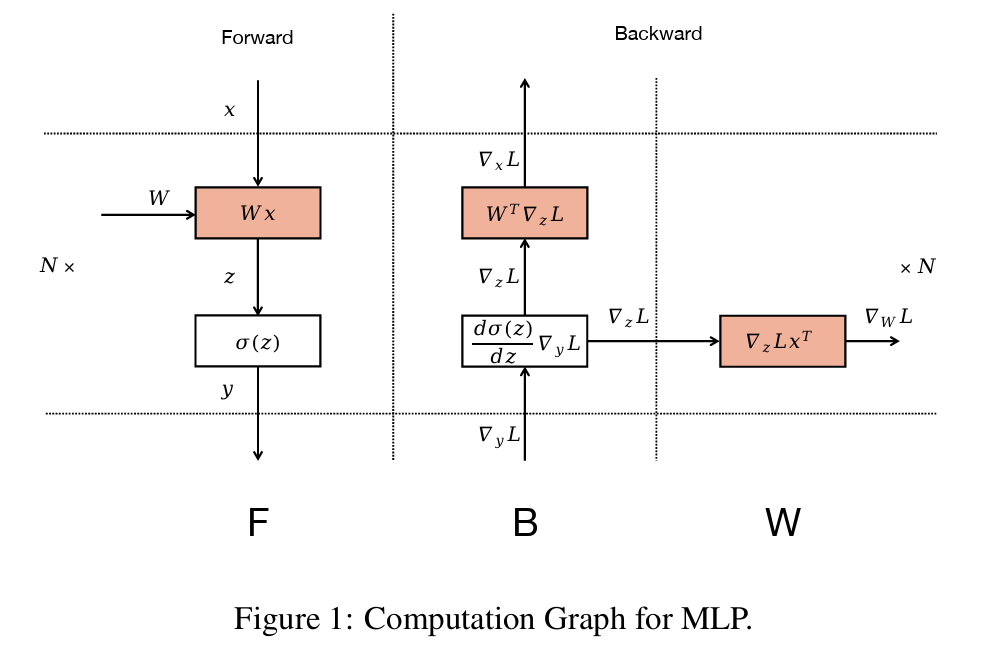
I have done that previous with matrix calculus, but it can be tedious. Is there a simple way to do the derivation? Einstein notation comes to rescue. For those who are not familiar with Einstein notation, you can check this website for more details.
For the MLP layer shown in the figure, the forward pass is pretty straightforward:
Here, the loss is a scalar. We can express it using Einstein notation by first defining the error term:
so that
Differentiating L with respect to y_i yields
where the negative sign appears because the error is defined as
Next, applying the chain rule, the gradient with respect to is
Now, let’s derive the gradient with respect to the weight matrix . Since
the derivative with respect to an element is
In matrix form, this can be neatly written as
Using Einstein notation, we focus on individual scalar components rather than entire vectors or matrices, which simplifies the derivation. You can apply the same process to the input x to compute its gradient.