- Published on
Cheap and Stable Way to run DL workload
- Authors

- Name
- Rand Xie
- @Randxie29
Recently, I started to get very obsessed with stable diffusion. In order to work with large DL models, you certainly need GPU resources. In this blog post, I will share with you the cheapest and most stable way to run these DL models. To decide what's the best way for you, firstly think about the usage pattern. And the metric is pretty simple: do you need to run DL training 7-24?
Solution for 7-24 Training
Previously, I was a heavy Kaggle user and I participated in many competitions. Over that period, I run DL/ML training almost 7-24. If your usage pattern fits into this case, then building your own DL workstation is the most cost-effective. And that's what I did back in 2017:
- Find DL workstation hardware list in PC partpicker based on your budge
- Purchase all the hardware and assemble yourself
- Set up your own linux machine and install nvidia drivers
- Run trainings 7-24
This solution helped me win a Gold medal and several silver medals in Kaggle. And the workstation is still used daily, except that I am not using it for DL training any more. One of the main reasons is that my Nvidia 1080 is quite outdated, and can not load the stable diffusion model. It's a good investment to build your own workstation if you anticipated heavy DL training workload.
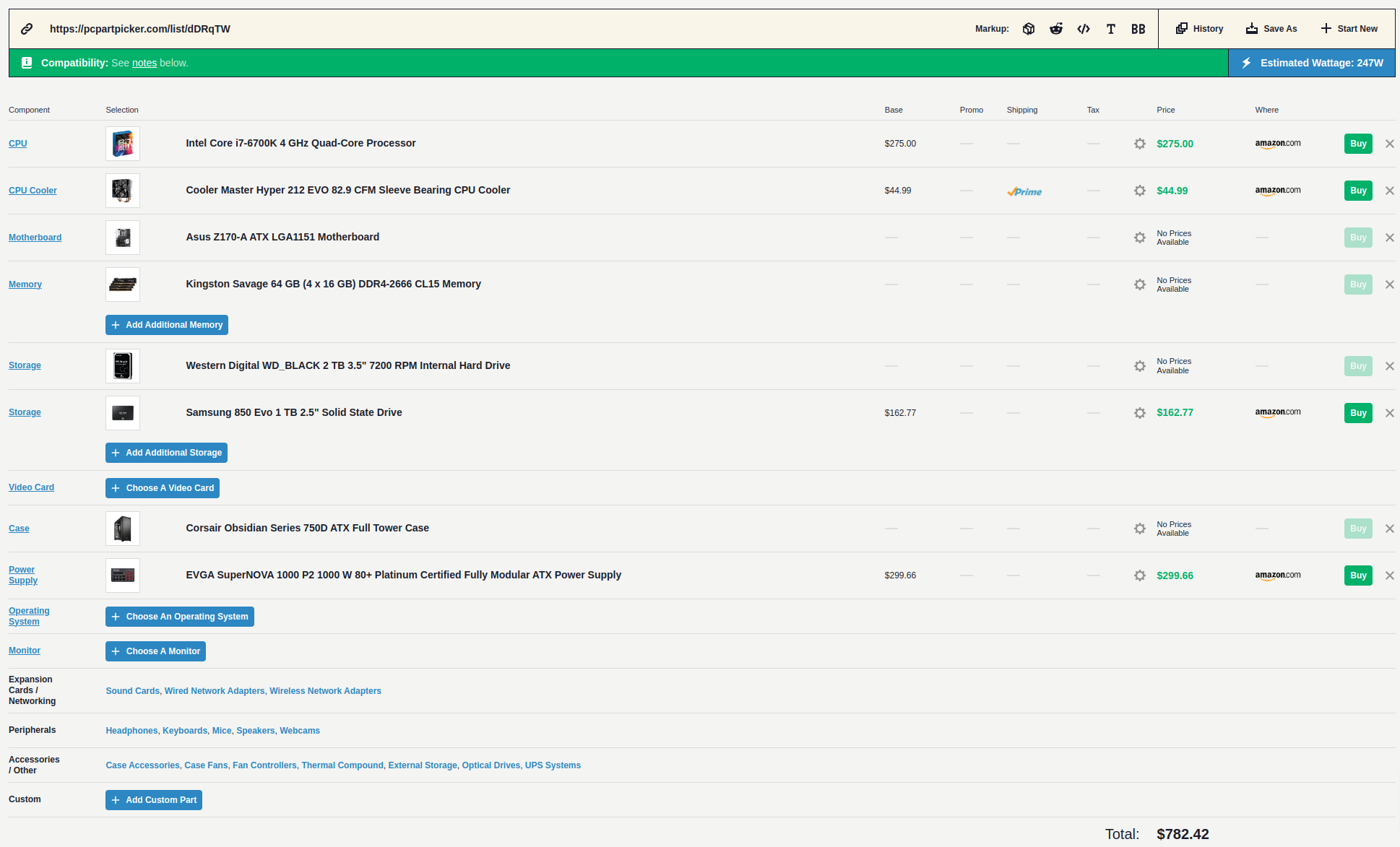
This is my DL workstation part list. The GPU is not included in the list and it's the most costly part. I also upgraded all disk to SSD because it will impact data loading time.
Solution for adhoc GPU training
As I keep climbing the career laddar and my baby arrives, I don't have the luxury to run DL training 7-24. But I still want to spend 2 hours per day to explore latest DL research. At the same time, my GPUs are quite outdated, and I don't have the time to upgrade them, as it also involves upgrading the motherboard and power supply. To satisfy my adhoc DL training need, I have explored multiple solutions, including:
- Colab Pro membership (gives you a T4 for 50+ hours or A100 for 10+ hours.)
- Small GPU rental providers like Lambda GPU cloud or Vast.ai.
- GCP DLVM solution
I will list out their pros and cons based on my observations.
Colab
Pros:
- Zero configuration - Just open and Use.
- Be able to pick between T4 and A100 (high-mem GPUs).
- Similar cost as using spot instances on GCP.
Cons:
- Only expose notebook interface, harder to integrate with your IDE, e.g. VS Code.
- If you are an engineer, notebook is not a structured format for development.
- Need to run
pip installfor your custom packages after stopping the runtime.
Lambda GPU cloud or Vast.ai
I did not make this path to work. In general, these small GPU rental vendors have worse UI and usability compared to cloud providers like GCP or AWS. They also do not have much price advantages compared to Cloud providers' spot instances. For Vast.ai, if you want to get similar price as GCP's spot instance, you need to use their bidding model that's hard to reason about.
[Preferred] GCP DLVM
After running the workload on Colab for a while, I finally settle down with GCP DLVM.
Pros:
- Can use VS Code to ssh into the VM that provides smooth development experience (tutorial here). You can install Python extension in VS code to index code in the VM and also open images directly.
- The spot instances are often available. I used T4 spot instance that gave me 16 GB GPU memory and only cost 0.11 dollar per hour. If you just run it for 4 hours per day, the monthly cost is only 13.2 dollar.
- DLVM automatically installs nvidia driver for you!!! One biggest pain point for building your own DL workstation is that Nvidia-driver can break your system. GCP DLVMs will not have such issues.
- Pretty quick to restart the VM after it' stopped.
Cons:
- Need to manually stop the VMs to reduce cost. There are solutions to auto shutdown idle VMs by monitoring the CPU usages. I haven't tried that yet.
- Need to apply for quotas to run T4/A100 instances.
As you can tell, the pros are very obvious for the GCP DLVM solutions, both in terms of cost, development experience and usability. Just two small tips if you decided to go with this path:
- Make sure you selected the spot instance, the cost saving is significant
- Make sure you use DLVMs to save you the effort to install conda, nvidia-driver, pytorch, etc.
Conclusion
To conclude, if you need to run continuous DL training, then building your own DL workstation is optimal. If not, using GCP DLVMs are the best solution that I have found until now.